Jeffrey Tumminia, Amanda Kuznecov, Sophia Tsilerides, Ilana Weinstein, Brian McFee, Michael Picheny, Aaron R. Kaufman.
Under review.
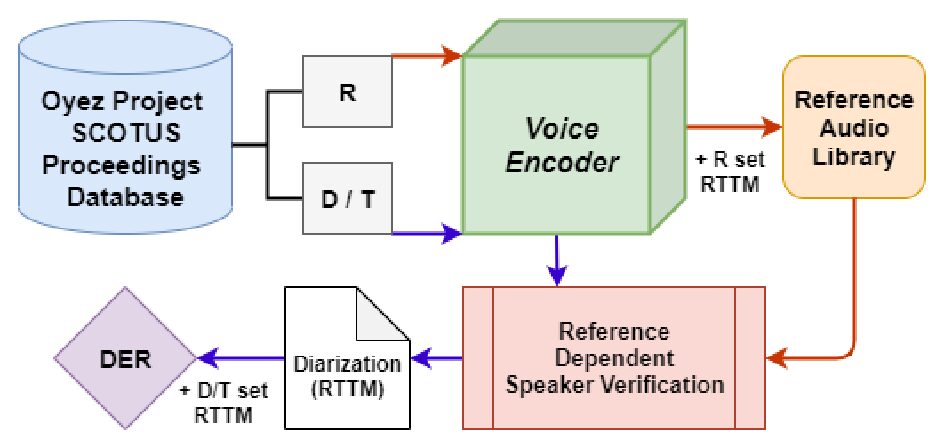
United States Courts make audio recordings of oral arguments available as public record, but these recordings rarely include speaker annotations. This paper addresses the Speech Audio Diarization problem, answering the question of “Who spoke when?” in the domain of judicial oral argument proceedings. We present a workflow for diarizing the speech of judges using audio recordings of oral arguments, a process we call Reference-Dependent Speaker Verification. We utilize a speech embedding network trained with the Generalized End-to-End Loss to encode speech into d-vectors and a pre-defined reference audio library based on annotated data. We find that by encoding reference audio for speakers and full arguments and computing similarity scores we achieve a 13.8% Diarization Error Rate for speakers covered by the reference audio library on a held-out test set. We evaluate our method on the Supreme Court of the United States oral arguments, accessed through the Oyez Project, and outline future work for diarizing legal proceedings. A code repository for this research is available at github.com/JeffT13/rd-diarization.